
I started rereading the papers I skimmed last year, and this time the Dynamo paper hit different. Not because the ideas are new, but because I finally understood why every design decision exists. So I did what any reasonable person would do: I spent a week building the whole thing from scratch.
The result is plethora - about 1500 lines of Go, 60 tests, all 9 key techniques from the paper. Before you get excited: this is not production software. All nodes run in a single process, storage is in-memory, there's no disk persistence. It's a learning project. But the algorithms are real, the nodes talk over real gRPC, and the tests spin up actual servers on random ports.
Let me walk you through how I built it, bottom-up, one problem at a time. Each layer exists because the previous one left a gap.
First, What Even Is Dynamo?
Dynamo is Amazon's internal key-value store. The paper came out in 2007 and it changed how people think about distributed databases. The core idea is deceptively simple:
Availability over consistency.
Amazon's shopping cart is the motivating example. Imagine a customer adds items to their cart. That write must succeed. If a data center is on fire, if nodes are crashing, if the network is partitioned, the customer should still be able to add to their cart. Losing a write means losing revenue. Amazon would rather show you a slightly stale cart than show you an error page.
This is the opposite of how traditional databases work. A MySQL primary will reject your write if it can't confirm it's been safely replicated. That's strong consistency, you always read what you last wrote, but sometimes you can't write at all. Dynamo flips this: you can always write, but when you read, you might get slightly stale data, or even multiple conflicting versions. The system will sort itself out eventually.
This tradeoff has a name: eventual consistency. It means:
- Writes are never rejected (as long as at least one node is reachable)
- Reads might return old data temporarily
- But given enough time and network connectivity, all replicas will converge to the same state
The "eventually" part is not hand-waving. Dynamo has concrete mechanisms to make convergence happen: vector clocks track causality, anti-entropy repairs divergence, gossip detects failures. Every technique in the paper exists to make "eventually" happen faster and more reliably.
There's a deeper idea here too. In traditional databases, the database resolves conflicts (last-write-wins, or reject the write). In Dynamo, the application resolves conflicts. When you read a key and get two conflicting versions, your application decides what to do. For a shopping cart, you merge them (union of items). For a user profile, you might pick the latest. This is called semantic reconciliation and it's why Dynamo stores a context (vector clock) with every value - so the application has enough information to make that decision.
Storage That Never Says No
Most key-value stores have a simple contract: one key, one value. Put("name", "alice") replaces whatever was there before. Dynamo can't do this because it allows concurrent writes from multiple nodes. Two nodes might accept writes to the same key at the same time with no coordination between them.
So our storage maps each key to a list of values:
gotype Storage struct { lock sync.RWMutex data map[Key][]Value // key -> list of concurrent versions }
When you Get("name"), you might get back ["alice", "bob"]. Both values are valid. They were written concurrently and neither one is "more correct" than the other. The application gets to decide which one wins (or if it should merge them).
But we can't just blindly accumulate values forever. If someone reads a value, modifies it, and writes it back, the old version is no longer relevant, the new one causally supersedes it. We need a way to detect this. That's where vector clocks come in.
Vector Clocks - Tracking Who Knows What
Here's the problem with timestamps in distributed systems: clocks lie. Node A's clock might say 3:00:01pm, Node B's might say 3:00:03pm. If both write to the same key, comparing timestamps tells you nothing about which write knew about the other. Maybe B's write came first in real time but A's clock is fast. Maybe they wrote simultaneously and neither knew about the other.
What we actually care about is causality. Did write B happen after seeing write A? Or did they happen independently?
A vector clock solves this. It's a map from node IDs to counters:
{node-1: 3, node-2: 1}
This means: "this value incorporates 3 writes from node-1 and 1 write from node-2." Every time a node writes, it bumps its own counter. When you read before writing (the read-modify-write pattern), the new clock inherits all the entries from the value you read.
Two clocks can be compared:
go// Descends returns true if vc happened after (or at the same time as) other func (vc VClock) Descends(other VClock) bool { for nodeID, version := range other { if vc[nodeID] < version { return false } } return true }
If clock A has every entry >= clock B, then A happened after B. This means A saw B (or something that saw B). B is an ancestor, it's safe to discard.
If neither clock descends from the other, the writes are concurrent. Neither writer saw the other's value. Both are equally valid.
Let's trace through an example:
1. client writes "alice" through node-1 clock: {node-1: 1} 2. client reads "alice", gets clock {node-1: 1} client writes "alice-updated" through node-1 clock: {node-1: 2} {node-1: 2} descends from {node-1: 1}, so "alice" is dropped. storage: ["alice-updated"] 3. two clients read "alice-updated" simultaneously client A writes "version-A" through node-1 -> clock: {node-1: 3} client B writes "version-B" through node-2 -> clock: {node-1: 2, node-2: 1} neither descends from the other! concurrent siblings. storage: ["version-A", "version-B"]
This gives us smart conflict resolution in storage:
gofunc (s *Storage) Put(key Key, val Value) { existing := s.data[key] var kept []Value for _, ev := range existing { if ev.Clock.Descends(val.Clock) { return // existing is newer, ignore this write } if val.Clock.Descends(ev.Clock) { continue // new value supersedes, drop the old one } kept = append(kept, ev) // concurrent, keep both } s.data[key] = append(kept, val) }
Three outcomes, every time:
- Existing descends from new: new write is stale, throw it away
- New descends from existing: existing is an ancestor, replace it
- Neither descends: concurrent conflict, keep both as siblings
This is the core of Dynamo's consistency model. We never reject a write. We never silently overwrite. We keep everything that's causally distinct, and let the reader deal with it later. Consistency is lazy here - it happens when someone reads, not when someone writes.
The Node
A node wraps storage with an identity and a hint store (we'll need this for hinted handoff later):
gotype Node struct { NodeID string Addr string Storage *storage.Storage HintStore map[string][]HintedItem }
There are three write paths, each for a different situation:
Put(key, val)- builds a clock, stores. Used in unit tests.Store(key, val)- takes a pre-built value, stores as-is. Used by the ring to replicate an already-prepared value. The coordinator builds the clock once, and all replicas store the exact same value.StoreHint(targetNodeID, key, val)- stores in a separate hint store, tagged with the intended owner. Never shows up inGet. It's a temporary holding pen.
Why three? Because in a replicated system, the coordinator node is the one that increments the clock. The other N-1 replicas just store the value the coordinator gave them. And sometimes a stand-in node holds data that isn't even meant for it. Each scenario needs different behavior.
Consistent Hashing: Distributing Keys
Now we need to spread keys across nodes. The naive approach - hash(key) % numNodes - breaks catastrophically when nodes join or leave. If you have 10 nodes and add an 11th, hash % 10 and hash % 11 give different results for almost every key. You'd need to move nearly all your data. That's not going to work.
Consistent hashing solves this. The Dynamo paper describes three strategies:
Strategy 1 - each node picks T random positions on the hash ring. Keys are assigned to the nearest node clockwise. The problem: when a node joins, it picks random positions that split existing ranges unevenly. Data transfer during membership changes is unpredictable and requires scanning.
Strategy 2 - same random positions, but decouple key ownership from partitioning. Keys hash to positions on the ring, but the partition structure adapts. Better than Strategy 1 but still has the "random positions" problem where load balance depends on randomness.
Strategy 3 - what we use. Forget random positions entirely. Divide the hash space into Q equal-sized partitions upfront and assign them round-robin:
gopartitions := make([]Partition, q) for i := 0; i < q; i++ { partitions[i] = Partition{ ID: i, Token: Token{NodeID: nodes[i%s].NodeID}, } }
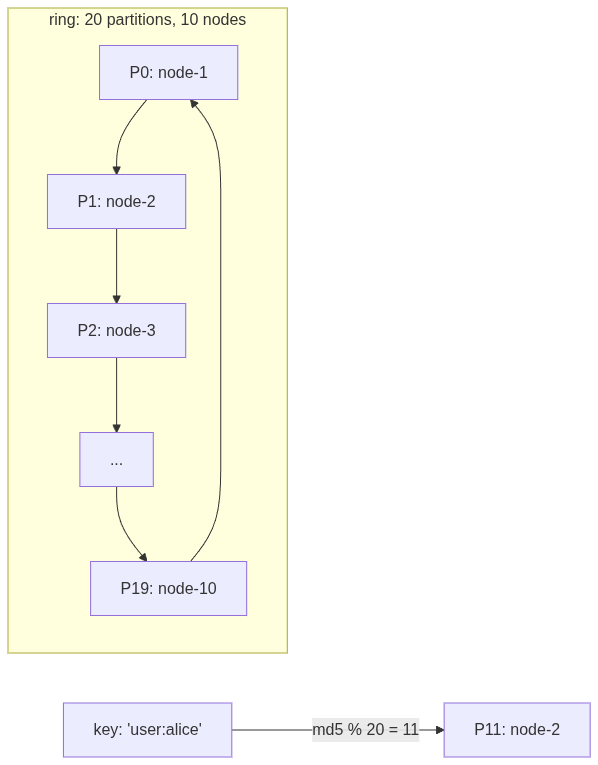
With Q=20 and 10 nodes, each node owns exactly 2 partitions. The boundaries never move. Adding a node just means reassigning some partitions. No data rehashing. Lookup is O(1):
gofunc (r *Ring) Lookup(key string) *node.Node { hash := md5Hash(key) partitionID := int(hash % uint64(r.Q)) ownerID := r.Partitions[partitionID].Token.NodeID return r.NodeMap[ownerID] }
Hash the key, mod by Q, look up who owns that partition. Done. The paper recommends Strategy 3 because it gives even load distribution, deterministic partition assignment, and simple data transfer during membership changes.
Replication and Sloppy Quorum: The Availability Trick
A single copy of data on one node is a disaster waiting to happen. If that node goes down, the data is gone (well, in our case it's in-memory so it's really gone, but even with persistence, it's unreachable).
Dynamo replicates each key to N nodes. The preference list for a key walks the ring clockwise from the key's partition and collects N distinct nodes. With N=3, every key lives on three nodes.
Now, here's where it gets interesting. Traditional quorum says: to write, you need W nodes to acknowledge. To read, you need R nodes to respond. As long as R + W > N, at least one node in the read set has the latest write. With N=3, R=2, W=2: 2+2 > 3, so you're guaranteed to read the latest write.
But strict quorum means if 2 out of 3 nodes are down, you can't write. That violates Dynamo's "always writable" guarantee. Enter sloppy quorum: when a preferred node is down, don't fail. Find the next healthy node on the ring and use it as a stand-in. The stand-in stores the data temporarily and hands it back when the real owner recovers.
This is the key insight of Dynamo. You don't need the specific W nodes to acknowledge. You need any W healthy nodes. The preference list just shifts to accommodate failures:
gotype Target struct { Node *node.Node HintFor string // empty = preferred node, non-empty = stand-in }
Our preference list builds this in two passes:
- First pass: walk the ring, find the N ideal preferred nodes, ignoring health
- Second pass: walk again. Preferred + alive = regular target. Preferred + dead = queue for stand-in. Non-preferred + alive + dead queue non-empty = stand-in covering the first dead preferred node.
goif preferred[nid] { if r.isAlive(nid) { targets = append(targets, Target{Node: r.NodeMap[nid]}) } else { deadPreferred = append(deadPreferred, nid) } } else if r.isAlive(nid) && len(deadPreferred) > 0 { targetID := deadPreferred[0] deadPreferred = deadPreferred[1:] targets = append(targets, Target{Node: r.NodeMap[nid], HintFor: targetID}) }
This makes Put beautifully simple. It just iterates targets; if HintFor is empty, it's a regular put. If not, it's a hinted put:
gofor _, t := range targets { if t.HintFor == "" { if client.RemotePut(t.Node.Addr, key, value) == nil { acks++ } } else { if client.RemoteHintedPut(t.Node.Addr, key, value, t.HintFor) == nil { acks++ } } }
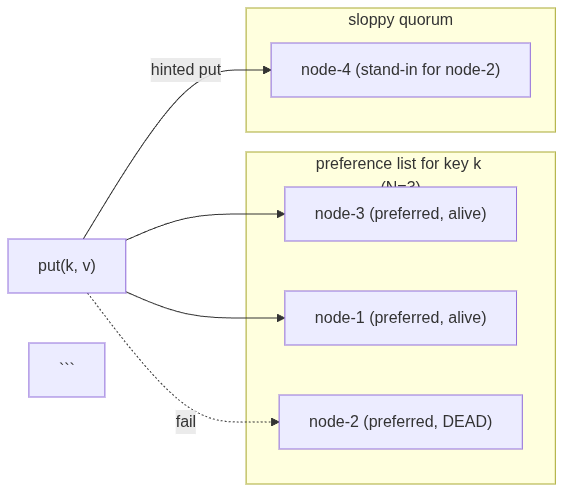
The write succeeds with 3 acks (>= W=2). The customer's cart item is saved. Node-2 is on fire. Nobody cares. Availability is preserved.
gRPC - Making It Real
Everything so far was in-process function calls. A distributed system needs actual network communication. We use gRPC with protobuf:
protobufservice KV { rpc Put(PutRequest) returns (PutResponse); rpc Get(GetRequest) returns (GetResponse); rpc HintedPut(HintedPutRequest) returns (PutResponse); rpc GetKeyHashes(GetKeyHashesRequest) returns (GetKeyHashesResponse); rpc SyncKeys(SyncKeysRequest) returns (SyncKeysResponse); rpc Gossip(GossipRequest) returns (GossipResponse); }
Six RPCs. First three: reads and writes. Next two: anti-entropy (merkle trees). Last one: gossip protocol. Each node runs a gRPC server. The ring talks to nodes through thin client wrappers.
The tests are the fun part - they spin up real gRPC servers on random OS-assigned ports:
golis, _ := net.Listen("tcp", "localhost:0") // OS picks the port srv := server.NewServer(n, seeds, replicaPeers, tFail) go srv.Start(lis)
No mocks. Real servers. Real network calls. When a test kills a node, it actually stops the gRPC server and the connection fails for real.
Hinted Handoff - Getting Data Back Home
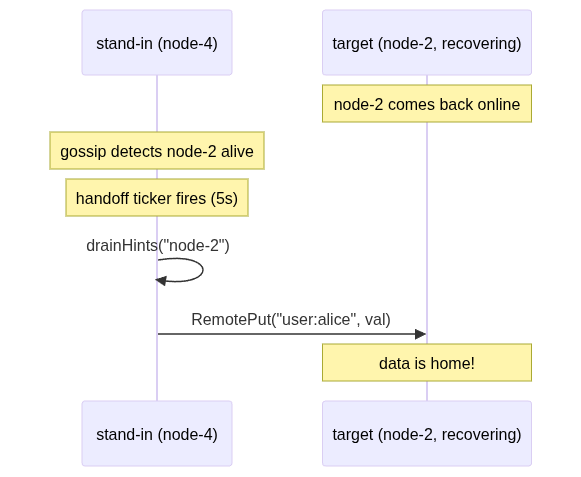
The stand-in saved the data. Great. But it's on the wrong node. The data for key user:alice is sitting on node-4, but node-2 (the rightful owner) doesn't know it exists. When node-2 recovers, we need to move that data back.
Each server runs a background goroutine on a 5-second ticker:
gofunc (s *Server) runHandoff() { ticker := time.NewTicker(5 * time.Second) defer ticker.Stop() for range ticker.C { for _, m := range s.members.Alive() { items := s.node.DrainHints(m.NodeID) for _, item := range items { client.RemotePut(m.Addr, item.Key, item.Value) } } } }
Every 5 seconds: check who's alive (via gossip), drain any hints destined for them, forward via regular RemotePut. DrainHints is atomic - it returns all hints and deletes them in one operation. Each hint is forwarded exactly once.
Hints live in a separate store. They never show up in Get responses. They're invisible to the outside world - just temporary holding pens waiting for the real owner to come back. Once forwarded, they're gone. The stand-in goes back to its normal life. (It never asked for this responsibility.)
Merkle Trees - Catching What Hinted Handoff Misses
Hinted handoff handles known failures, node was down, stand-in picked up the slack. But what about silent divergence? Maybe a put partially succeeded (2 out of 3 replicas got it, the third's network packet got dropped). Maybe a bug corrupted one replica's storage. Maybe a cosmic ray flipped a bit. (Okay probably not that last one. But you get the idea.)
The point is: replicas can drift apart without anyone noticing. We need a background process that periodically checks: "hey, do we still agree on everything?"
This is anti-entropy, and the efficient way to do it is with merkle trees.
A merkle tree is a binary hash tree. The leaves are hashes of individual key-value pairs. Each parent node's hash is computed from its children's hashes. The root hash is a fingerprint of the entire dataset.
[root: a1b2c3] / \ [left: d4e5] [right: f6a7] / \ / \ [key:a] [key:b] [key:c] [key:d]
The magic: if two trees have the same root hash, all data is identical. You're done. One comparison. If roots differ, walk down: compare left children. If they match, the divergence is on the right side. Keep going until you find exactly which leaves differ. That's O(log n) comparisons instead of comparing every single key.
gofunc Diff(a, b *MerkleNode) []string { if a == nil && b == nil { return nil } if a == nil { return collectKeys(b) } if b == nil { return collectKeys(a) } if a.Hash == b.Hash { return nil } // subtree in sync! if a.Left == nil && b.Left == nil { // both are leaves - this specific key diverged return []string{a.Key} } // recurse into children return append(Diff(a.Left, b.Left), Diff(a.Right, b.Right)...) }
Every 30 seconds, each server picks a replica peer (a node that shares some of its key ranges), fetches their key hashes, builds both merkle trees locally, diffs them, and syncs only the divergent keys:
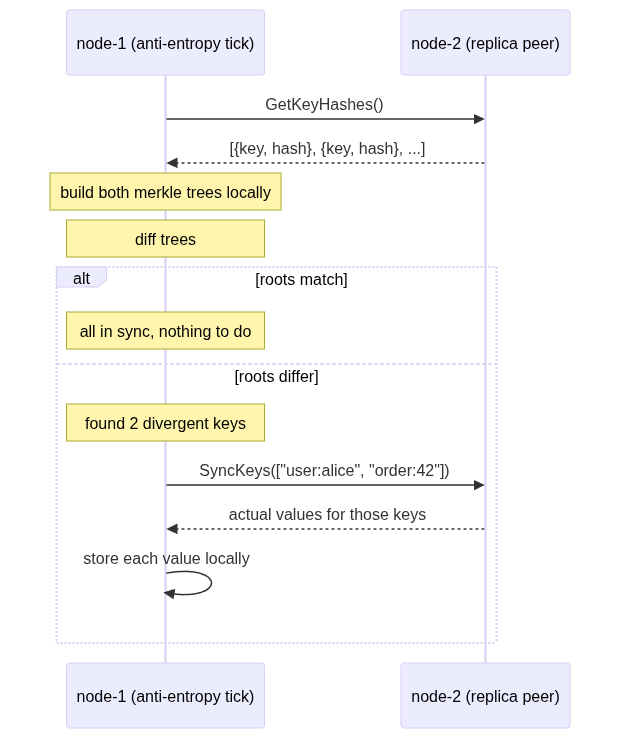
Important detail: the merkle tree never goes over the wire. Only flat key-hash pairs and actual values cross the network. Each node builds the tree locally. The tree is a local optimization for efficient comparison, not a data structure that needs serialization.
The node also caches its merkle tree with a dirty flag - every write marks it dirty, and MerkleTree() rebuilds lazily only when someone asks. No point rebuilding a tree nobody's looking at.
This is the "eventual" in eventual consistency made concrete. Even if everything else fails - hinted handoff didn't fire, a write was partially lost - anti-entropy will catch it within 30 seconds and repair the divergence. Given enough time, replicas always converge.
Gossip Protocol - Who's Alive, Who's Dead
All of the above depends on one thing: knowing which nodes are alive. The preference list needs to know who's dead to pick stand-ins. Hinted handoff needs to know who recovered. Anti-entropy needs to skip dead peers.
A centralized health checker would work, but that's a single point of failure, exactly what Dynamo avoids. Instead, Dynamo uses a gossip protocol. It's called gossip because it works like actual gossip: you tell a friend, they tell a friend, eventually everyone knows.
Each node maintains a membership list. Each entry has:
- NodeID and address: who and where
- Heartbeat counter: a monotonic number, only incremented by the owning node
- Timestamp: local wall time when we last saw this node's heartbeat increase
Every second, each node:
- Increments its own heartbeat counter
- Picks a random known peer
- Sends its full membership list
- Receives the peer's list back
- Merges: for each entry, keep the higher heartbeat
gofunc (m *MemberList) Merge(remote []MemberEntry) { now := time.Now() for _, r := range remote { if r.NodeID == m.selfID { continue } local, exists := m.members[r.NodeID] if !exists { // new node! discovered through gossip m.members[r.NodeID] = &MemberEntry{ NodeID: r.NodeID, Addr: r.Addr, Heartbeat: r.Heartbeat, Timestamp: now, } } else if r.Heartbeat > local.Heartbeat { local.Heartbeat = r.Heartbeat local.Timestamp = now } } }
Failure detection is timestamp-based. If we haven't seen a node's heartbeat increase within tFail (say, 10 seconds), we consider it dead:
gofunc (m *MemberList) IsAlive(nodeID string) bool { e, exists := m.members[nodeID] if !exists { return false } return time.Since(e.Timestamp) < m.tFail }
The beautiful thing is transitive discovery. Nodes don't need to know the full cluster at startup. Each node starts with just 2 seed nodes. When node-1 gossips with node-2, it learns about everyone node-2 knows. Information spreads exponentially. In our demo with 10 nodes, each starting with only 2 seeds:
[GOSSIP] after 1s: each node sees 3/10 members [GOSSIP] after 3s: most nodes see 10/10 [GOSSIP] fully converged after 4s!
4 seconds for 10 nodes to fully discover each other, starting from knowing only 2 neighbors. Gossip is absurdly effective. And because RandomPeer() includes dead peers, we can also detect recoveries; if a dead node starts responding again, its heartbeat counter will jump and we'll mark it alive.
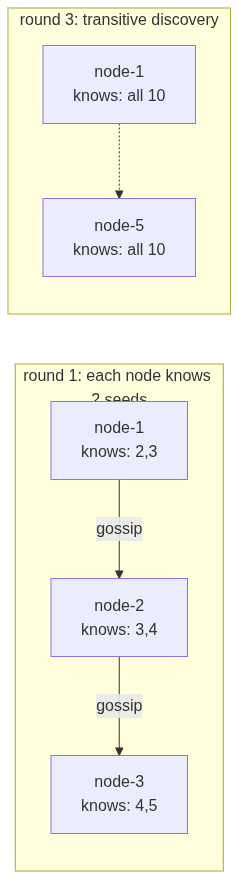
The ring's IsAlive callback reads directly from gossip state. When a node dies, gossip detects it within tFail seconds. The preference list automatically routes around it. When it recovers, gossip picks it up, handoff fires, data flows home. No manual intervention. No central coordinator. Just peers talking to peers.
The Three Background Loops
Every server runs three goroutines. Together, they make "eventual" happen:
| Goroutine | Interval | What It Does |
|---|---|---|
runGossip | 1s | Tick heartbeat, pick random peer, exchange membership lists |
runHandoff | 5s | Forward hints to recovered nodes |
runAntiEntropy | 30s | Compare merkle trees with replica peers, sync divergent keys |
Think of them as layers of a safety net:
- Gossip keeps the membership view fresh (who's alive, who's dead)
- Handoff recovers from known failures (data on wrong node)
- Anti-entropy catches everything else (silent divergence, missed writes)
If gossip fails, nodes can't detect recovery, so handoff won't fire. But anti-entropy will still eventually sync the data. If anti-entropy is slow, handoff gets the urgent stuff done fast. They're complementary. Belt and suspenders. Belt and suspenders and also a rope tied to the ceiling just in case.
The Full Picture
Here's a complete write flow with all layers working together:
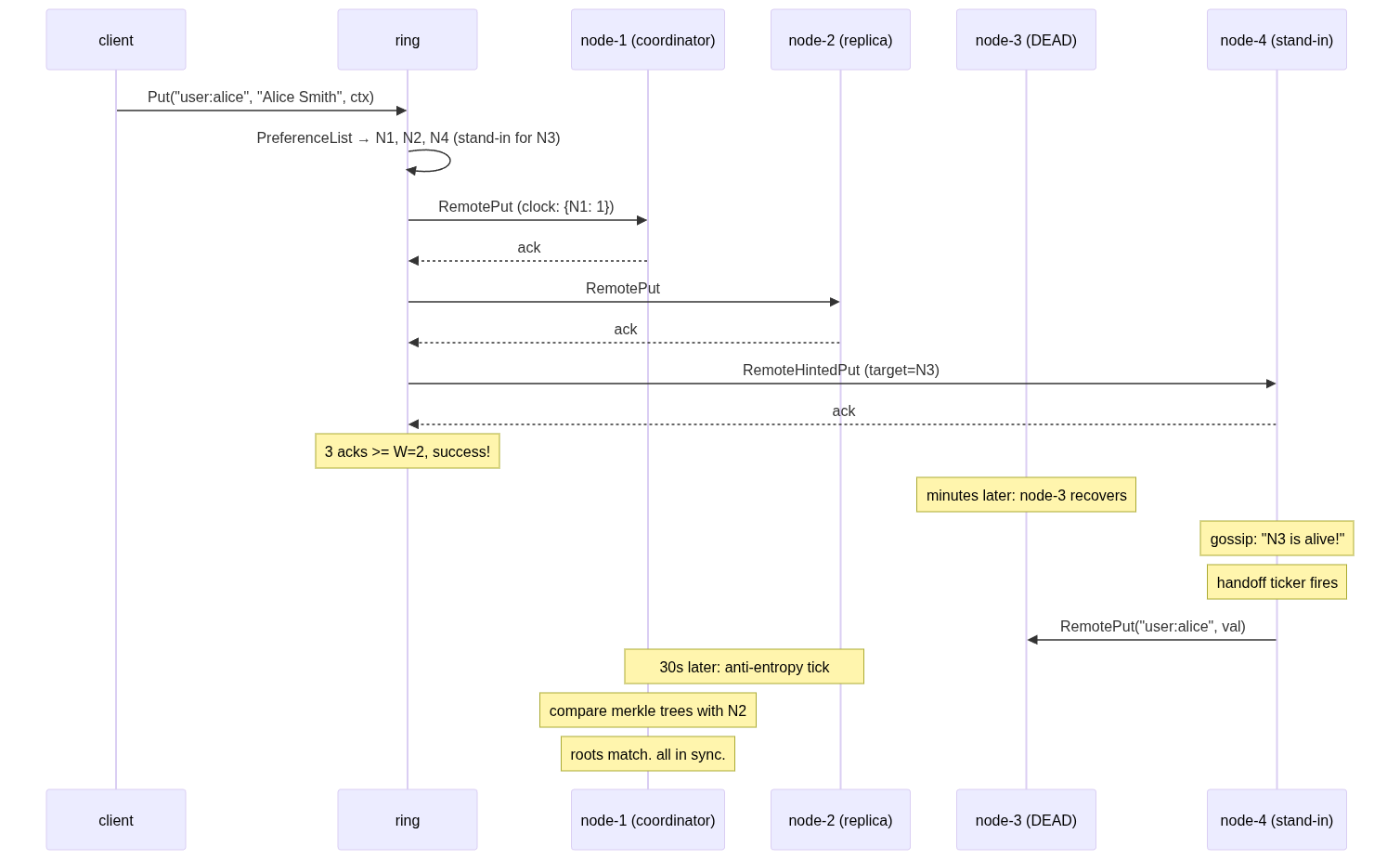
Every layer has a job. Storage accepts concurrent versions. Vector clocks track causality. Consistent hashing distributes keys. Sloppy quorum ensures writes always succeed. gRPC makes it networked. Hinted handoff gets data home. Merkle trees catch drift. Gossip keeps the membership view alive.
What This Doesn't Cover
Real talk: this is a learning implementation. Here's what production Dynamo has that we don't:
- Persistence - our storage is in-memory. A restart loses everything. Real Dynamo uses a write-ahead log and persistent storage (originally BDB, later custom).
- Multi-process - all our nodes run in one Go binary. Real Dynamo runs each node as a separate process on separate machines in separate racks.
- Dynamic ring - our ring topology is fixed at startup. Real Dynamo gossips partition ownership so nodes can join and leave without downtime.
- Read repair - we deduplicate on reads but don't write the resolved value back to stale replicas. Real Dynamo does this for faster convergence.
- Per-node ring view - we have one shared ring. In reality, each node has its own ring instance driven by its own gossip state.
These are engineering concerns, not algorithmic ones. The hard part of Dynamo is the algorithms, the consistent hashing, the vector clock causality, the sloppy quorum trick, the merkle tree diffing, the gossip convergence. Those are all here, working, tested.
Learnings
Building Dynamo changes how one thinks about correctness.
In a traditional database, correctness means "every read returns the last write." That's a clean, satisfying guarantee. Dynamo says: forget that. Correctness here means "no write is ever lost, and the system never stops accepting writes." Those are fundamentally different promises, and everything in the paper - vector clocks, sloppy quorum, merkle trees, gossip - exists to make the second promise work without the first one falling apart too badly.
The thing that surprised me most is what the paper doesn't do. There's no optimistic locking. No compare-and-swap. No way for a client to say "write this only if nobody else has written since I last read." If two clients read the same key, compute something, and write back - both writes succeed. You get siblings. The paper's answer is "the application merges them later." For a shopping cart, that's fine - take the union. For an inventory counter - say, "3 left in stock" - two concurrent decrements both succeed, both think they got the last valid item, and now you've oversold.
This is why DynamoDB (the actual AWS product) bolted on conditional writes and transactions years later. The paper's design is beautiful and internally consistent, but it only works for a specific class of applications - ones where conflicts can be resolved by simple merge logic, not ones where you need "this or nothing."
The other thing: availability isn't free. Dynamo trades consistency for availability, but the engineering cost of that trade is enormous. You need vector clocks to track causality. You need sloppy quorum so writes survive failures. You need hinted handoff to get data back home. You need merkle trees to catch silent drift. You need gossip so nodes can find each other without a coordinator. Nine techniques, all layered on top of each other, all because we refused to say "sorry, try again later" to a single write.
That's the real lesson. Choosing availability over consistency isn't the easy path - it's the harder one. You just pay the complexity cost in different places.
Join the Discussion
Have thoughts or questions? Share them below.
Sign in with GitHub to comment